「検索1位を取っているのに、アクセスが以前ほど集まらない」——そう感じているマーケター・SEO担当者が増えています。
原因のひとつは、GoogleのAI Overviewsに代表される生成AIによる検索体験の変化です。ユーザーが検索したとき、AIがページ内容を要約して直接回答を提示するようになったことで、リンクをクリックしなくても疑問が解決する「ゼロクリック検索」が広がっています。
この変化に対応するための最適化手法が、LLMO(Large Language Model Optimization:大規模言語モデル最適化)です。
本記事では、LLMOの定義から、なぜ今重要なのか、具体的に何をすべきかまでを、データをもとに体系的に解説します。
この記事でわかること
- LLMOの正確な定義と、SEO・AEO・GEOとの違い
- ゼロクリック時代がどこまで進行しているか(最新データ)
- AI Overviewsが出現しやすい検索クエリのパターン
- AI検索で引用されるために実践すべき施策
- 効果測定に使える3つの指標
LLMOとは
LLMO(Large Language Model Optimization:大規模言語モデル最適化)とは、ChatGPT・Google Gemini・Perplexityなどの大規模言語モデル(LLM)が回答を生成する際に、自社のコンテンツが引用・参照されたり、ブランドが推薦されたりするよう最適化する手法です。
日本国内ではLLMOという表記が主流ですが、海外ではGEO(Generative Engine Optimization:生成エンジン最適化)と呼ばれることが多く、同じ概念を指しています。「AEO(Answer Engine Optimization)」はより広く回答エンジン全般への最適化を指す場合もあり、定義が論者によって若干異なります。本記事では「LLMO」で統一します。
LLMOと従来のSEOは何が違うか
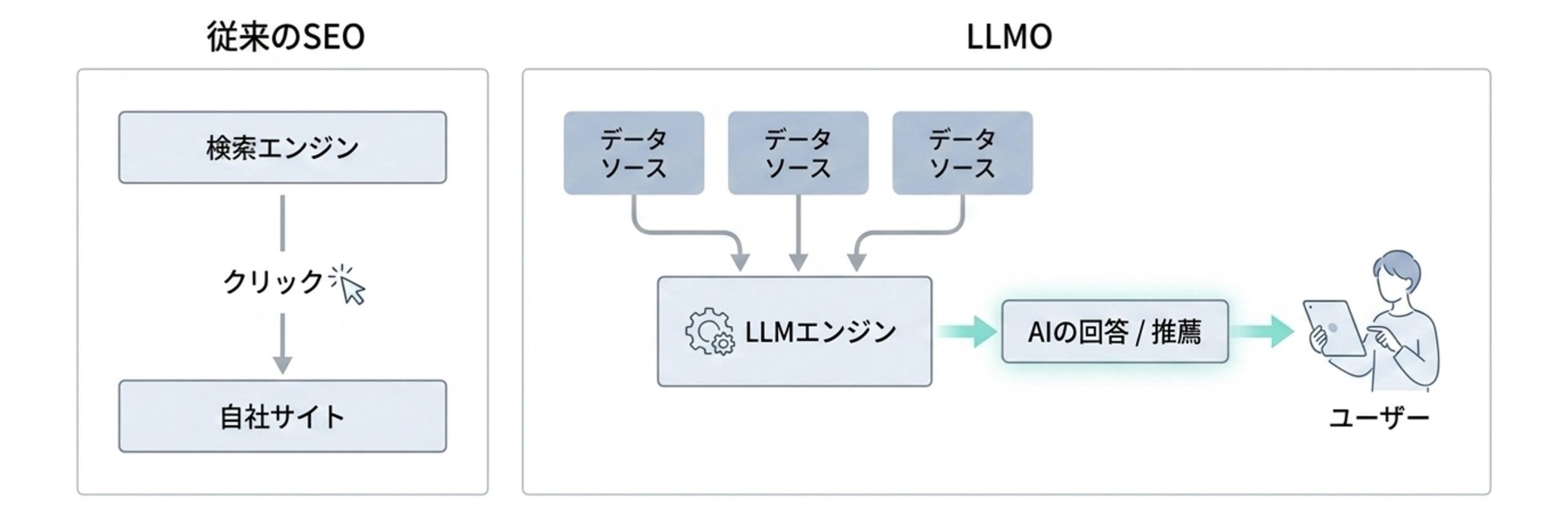
従来のSEO(検索エンジン最適化)の目的は、GoogleやYahoo!の検索結果で上位を獲得し、リンクのクリックを通じてサイトへ集客することでした。
LLMOは目的が異なります。AIが生成する回答の中で自社コンテンツが一次情報源として引用されること、あるいは「おすすめのツール・サービス」として言及されることが目標です。
ユーザーはサイトを訪問する前に、AIの回答内で企業・サービスの情報を目にします。つまりLLMOは、「AIを通じたブランド接触」という新しい認知経路を確保する施策でもあります。
なぜ今LLMOが重要なのか
ゼロクリック検索の進行と「グレート・デカップリング」
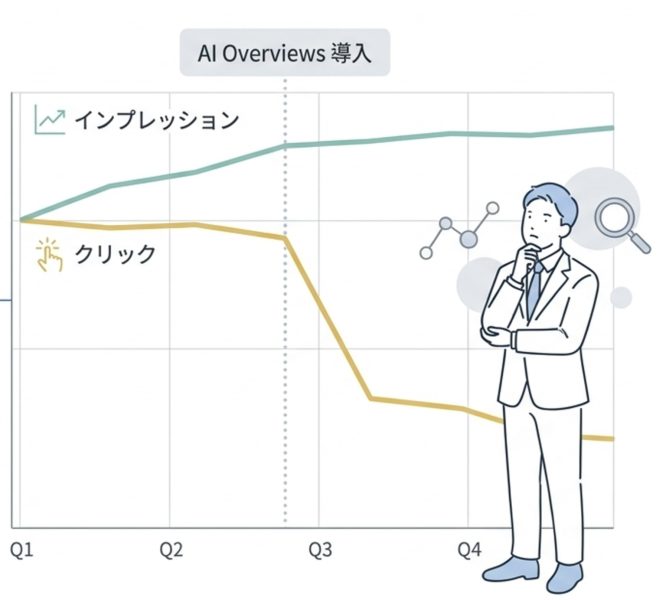
Ahrefsが2025年4月に発表した調査によると、AI Overviewsが表示された場合、情報系クエリ(「〇〇とは」など)における検索1位サイトのCTR(クリック率)は、2024年3月と比較して2.5ポイント低下しています。日本国内ではAI Overviewsが表示されるケースでCTRが約38%低下するとのデータもあります。
さらに注目すべきは、Search Console上でクリック数とインプレッション数が乖離する「グレート・デカップリング」と呼ばれる現象です。サイトは検索結果に表示されている(インプレッションは出ている)のに、クリック数だけが伸びない——このパターンが多くのサイトで確認されています。
ただし重要な前提があります。ゼロクリック検索はすべてのクエリで起きているわけではありません。
Ahrefsが1億4600万件のSERPを分析したデータでは、AI Overviewsの出現率は検索クエリの意図によって大きく異なります。
| 検索クエリの種類 | 例 | AI Overviewsの出現率 |
|---|---|---|
| 情報提供型 | 「LLMOとは」「確定申告のやり方」 | 99.9% |
| コマーシャル型 | 「SEOツール おすすめ」「CRM 比較」 | 5.5% |
| トランザクション型 | 「iPhone 購入」「ホテル 予約」 | 1.2% |
| ナビゲーション型 | 「YouTube」「Amazon」 | 0.1% |
(出典:Ahrefs「What Triggers AI Overviews? 86 Factors and 146 Million SERPs Analyzed」)
このデータが示すことは明快です。「〇〇とは」型の情報収集クエリはほぼ確実にAI Overviewsが表示される一方、「おすすめ」「比較」などのコマーシャルクエリではAIの介在度がまだ低い。つまり、LLMOへの取り組みに優先順位をつけるなら、情報収集型コンテンツから着手するのが現実的です。
AI検索が普及しても、検索エンジンは使われ続ける
「LLMOに注力すればSEOは不要」という誤解を持つ方もいますが、データはそれを支持しません。
ナイルが2025年10月に実施した調査によると、生成AIを利用するユーザーの8割以上が、AIが返した回答を検索エンジンで「裏取り」していることがわかっています。つまり「AIで調べる→検索で確認する」という行動パターンが定着しつつあります。
この流れを考えると、LLMOとSEOは競合するものではなく、相互補完の関係にあります。AIで自社ブランドを認知したユーザーが、指名検索でサイトを訪れる——という新しいファネルが生まれているのです。LLMOはSEO基盤の上に成立します。クローラビリティが低いサイト、E-E-A-Tが不十分なコンテンツは、LLMにも評価されません。
検索結果がクリックされなくなる「ゼロクリック化」の背景について詳しく知りたい方は、ゼロクリック検索とは?増加の理由と検索行動の変化・対策を参考にしてください。
LLMO・SEO・AEO・GEOの比較
| 用語 | 主な対象 | 目的 | 評価軸 |
|---|---|---|---|
| SEO | Google・Yahoo!などの検索エンジン | 検索結果での上位表示・クリック獲得 | 検索順位・CTR・オーガニック流入 |
| LLMO | ChatGPT・Gemini・Perplexityなど | AIの回答での引用・推薦・言及 | メンション数・サイテーション数・指名検索数 |
| AEO | 回答エンジン全般(AIアシスタント含む) | 直接回答での露出 | スニペット獲得率・音声回答採用率 |
| GEO | 生成エンジン全般 | 生成AIが返す回答での参照 | LLMOとほぼ同義(海外での呼称) |
表で整理した各概念は、個別記事でさらに詳しく扱っています。
- これらを含めたAI検索対策の全体像:AI検索時代のGEO(LLMO・AIO)対策|CEP起点の選ばれるブランド戦略
- AI Overviewの仕組みと引用対策:AIOとは?AI Overviewの仕組み・SEOへの影響・引用されるための対策を解説
- LLMが評価する信頼性の土台:E-E-A-Tとは?SEOの4要素と対策をAI検索時代の視点で解説
LLMはどのように情報を選ぶのか
LLMO施策を正しく設計するには、LLMが「なぜそのコンテンツを引用するのか」を理解することが重要です。
LLMが回答を生成するプロセスには大きく3段階があります。
① 事前学習: 書籍・Web記事・論文などの大量テキストを読み込み、言語のパターンと知識を学習します。この段階で、信頼性の高いサイトの情報ほど多く参照されます。
② 回答生成: ユーザーの質問に対して、学習したパターンから「最も適切な回答」を生成します。ここで引用されるコンテンツは、「明確な情報構造を持ち、信頼できる根拠を示しているもの」が選ばれやすい傾向があります。
③ リアルタイム参照(RAG): 必要に応じてWebを検索し、最新情報を取り込みます。PerplexityやChatGPT(Web検索機能)はこのプロセスで動いています。
つまりLLMOの本質は、「LLMが信頼できる情報源として認識し、繰り返し参照したいと判断するコンテンツを作ること」です。
AI検索で引用されるための施策
著者情報・監修者情報・一次資料・公開日や最終更新日を明示し、LLMが信頼できる情報源として評価しやすいコンテンツにする
自社調査・分析レポート・ユーザーデータなど、競合が持たない独自情報を数値や図表とともに示し、引用されやすい情報資産にする
H2・H3の見出し階層、FAQ、定義・メリット・注意点の明示、比較表を活用し、LLMが内容を理解しやすい構造に整える
特定テーマに関するサブトピックを網羅し、内部リンクで体系化することで、LLMに専門性の高いサイトとして認識されやすくする
業界メディアへの寄稿、比較サイトへの掲載、プレスリリース、専門家コメントなどを通じて、第三者からの言及を増やす
Organization、Article、FAQPage、Product / Serviceなどの構造化データを実装し、AIがサイトやブランド情報を正確に把握しやすくする
1. E-E-A-Tを軸にしたコンテンツ品質の強化
LLMは信頼できる情報源を優先します。Googleが提唱するE-E-A-T(経験・専門性・権威性・信頼性)は、LLMが情報の質を評価する際の基準にもなっています。
具体的に取り組むべきことは以下の通りです。
- 著者情報の明示: 記事の執筆者・監修者のプロフィールと実績を記載する
- 情報の根拠を示す: 主張の根拠となる一次資料(調査データ、研究論文、公式発表)を明記する
- 情報鮮度の管理: 公開日と最終更新日を管理し、古い情報は定期的に更新する
E-E-A-Tの評価基準については、関連記事「E-E-A-Tとは?SEOの4要素と対策をAI検索時代の視点で解説」を参考にしてください。
2. 一次データ・独自調査の公開
自社で実施したアンケート調査、分析レポート、ユーザーデータは、競合サイトが持てない独自情報です。数値・図表を伴う定量データは、LLMが引用しやすく、第三者メディアへの掲載(=サイテーション獲得)にもつながります。
調査の出典元(実施主体・実施時期・サンプル数・方法)を明記することが重要です。「誰が、いつ、どのように調べたか」が不明瞭なデータはLLMから信頼されません。
3. コンテンツ構造の最適化
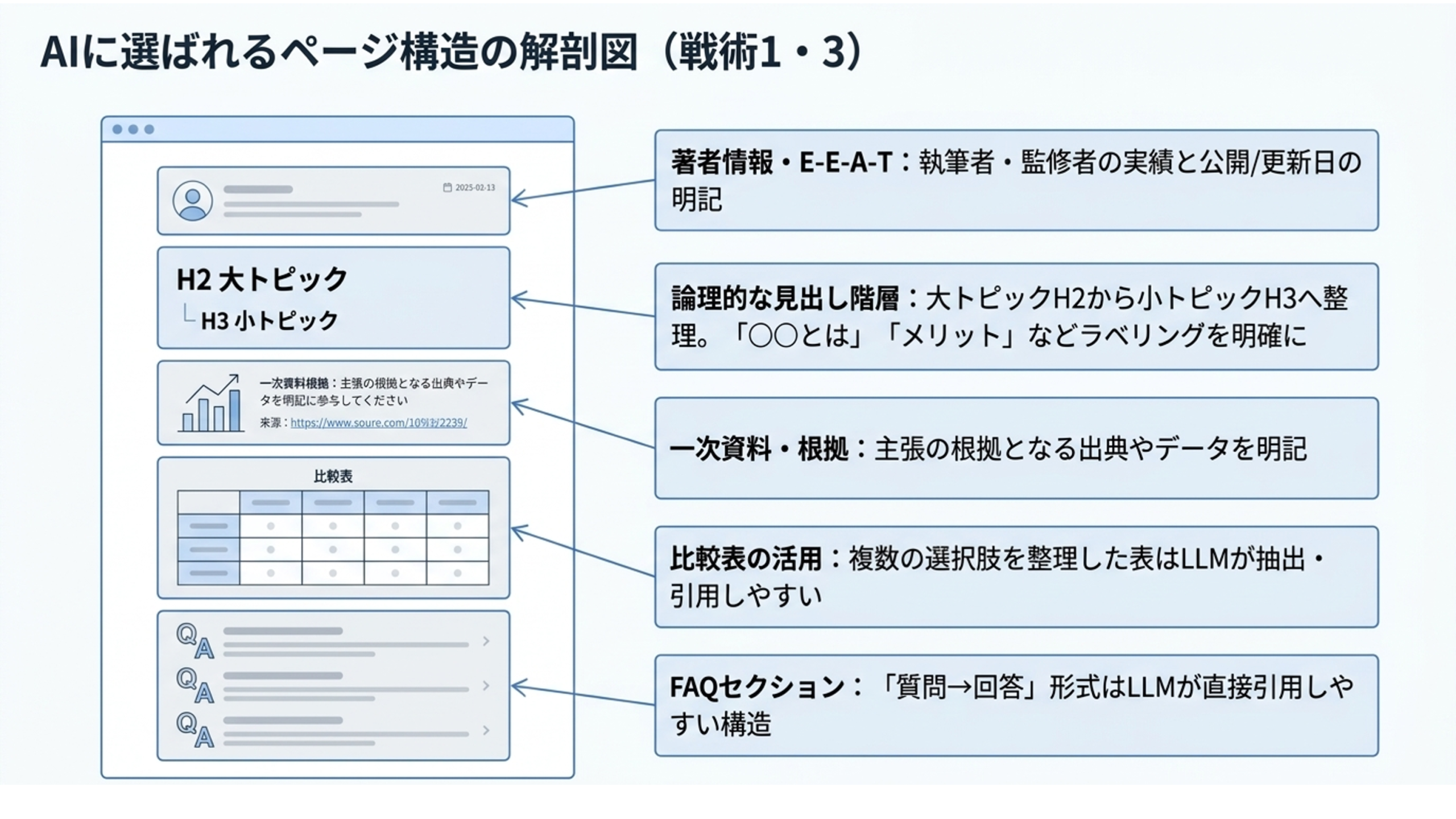
LLMは非構造化テキストより、論理的に整理されたコンテンツを理解しやすい傾向があります。次のような構造を意識して設計します。
- 見出し階層(H2・H3)の整理: 大トピックから小トピックへ論理的に流れるよう設計する
- FAQセクションの設置: 「質問→回答」形式はLLMが直接引用しやすい
- 定義・メリット・注意点の明示ラベリング: 「〇〇とは」「主なメリット」「注意点」など、セクションの役割を明示する
- 比較表の活用: 複数の選択肢を整理した表は、LLMが引用しやすく、ユーザーにとっても読みやすい
コンテンツSEOの構造設計については、関連記事「コンテンツSEOで検索順位を上げる具体的手法と実践ガイド」を参考にしてください。
4. トピッククラスターによる専門性の確立
特定テーマについて体系的なコンテンツ群を持つサイトは、LLMからそのテーマの権威として認識されやすくなります。単発の記事を量産するより、ひとつのテーマを深く・広くカバーするトピッククラスター戦略のほうがLLMOには有効です。
「このサイトはこのテーマに詳しい」とLLMに判断させるには、関連するサブトピックを網羅し、相互に内部リンクで結ぶ構造が必要です。
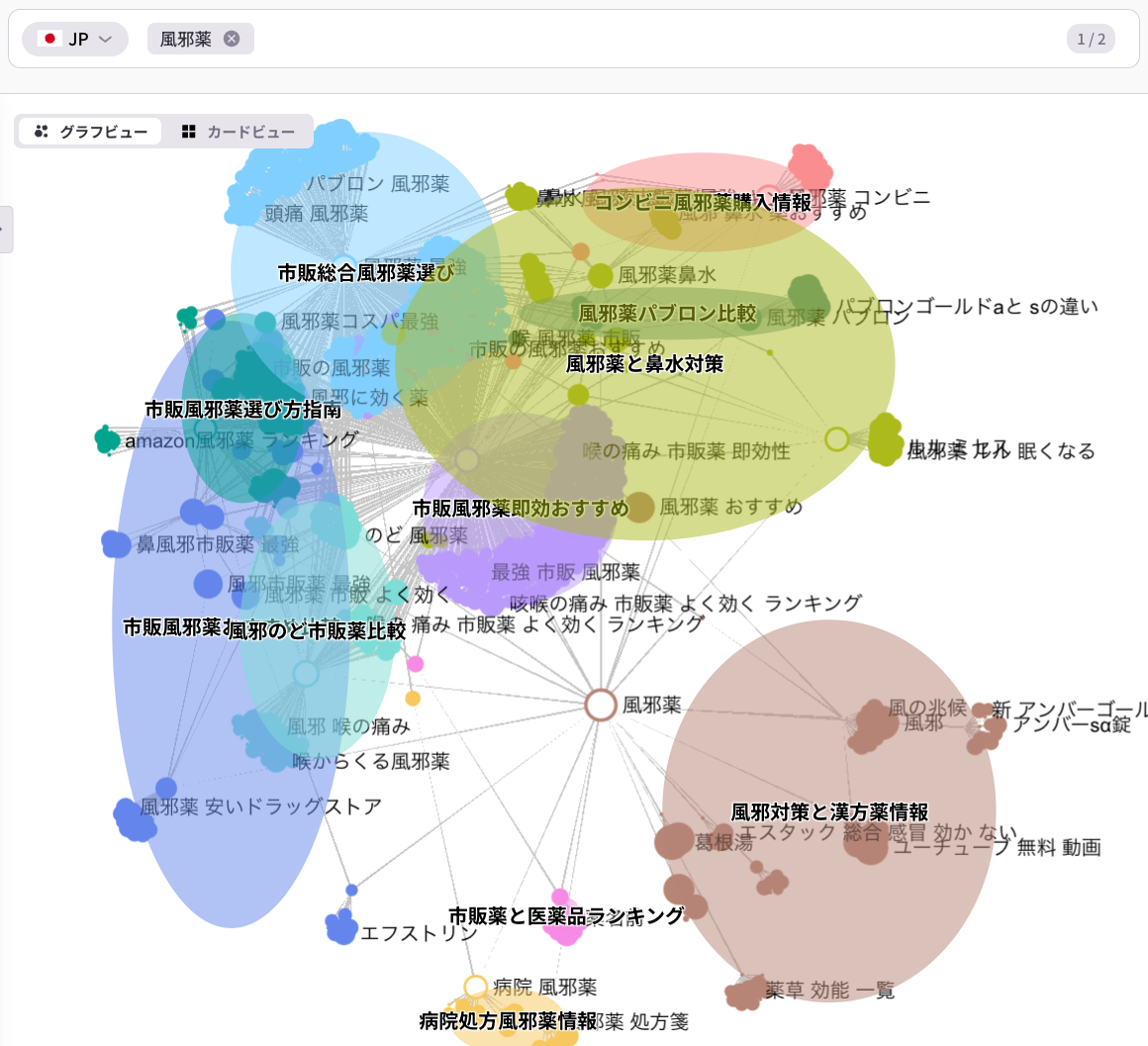
【ヒント】ListeningMindのクラスターファインダーでは、対象テーマに関連する検索クエリのセマンティッククラスターを可視化できます。「どのサブトピックまでカバーすれば、AIから専門サイトとして認識されるか」を把握するのに役立ちます。
5. サイテーション(外部言及)の獲得
LLMは「多くの信頼できるサイトから言及されているブランド・情報」を高く評価します。自社の公式サイトだけで訴求するのではなく、第三者メディアからの言及(サイテーション)を増やすことが、LLMOにおける最も重要な外部施策のひとつです。
サイテーション獲得のアプローチ:
- 業界メディアへの寄稿・取材対応
- 比較・ランキングサイトへの掲載
- プレスリリース配信による報道獲得
- 専門家コメントとして引用される一次情報の発信
「自社が良いと言っているだけ」ではAIは評価しません。第三者が言及しているという実績の積み上げが、AIによる推薦につながります。
競合他社のサイテーション状況を把握する方法については、関連記事「競合分析とは」を参考にしてください。
6. 構造化データの実装(過信は禁物)
schema.org形式の構造化データは、AIがWebサイトやブランドの情報を正確に把握する助けになります。
実装が有効とされるマークアップ:
Organization:企業名・所在地・事業内容Article:著者・公開日・更新日FAQPage:よくある質問と回答Product/Service:製品・サービス情報
ただし、構造化データ単体のLLMO効果は限定的というのが現時点での見解です。コンテンツ品質・E-E-A-T・サイテーションという本質的な施策を優先し、構造化データはその補助として実装する位置づけが適切です。構造化データへの過剰なリソース投入は費用対効果が見えにくく、ハイリスクです。
検索行動データでLLMO戦略を設計する
LLMOで見落とされやすい視点があります。それは「どのクエリでAIが介在しているかを、先に把握してから施策を設計する」ことです。
先述のAI Overview出現率データが示す通り、AIが回答を生成しやすいクエリとそうでないクエリでは、LLMOへの取り組みの優先度が変わります。自社のターゲットキーワードのどこにAIが入り込んでいるかを把握せずに施策だけ積み上げても、効率が悪くなります。
ステップ1:AI介在度が高いクエリを特定する
まず自社に関連するテーマで、「情報収集型(〇〇とは・〇〇の方法・〇〇の選び方)」のクエリがどれだけあるかを把握します。これがLLMO優先対象です。逆に「〇〇 料金」「〇〇 導入事例」などのコマーシャルクエリはAI介在度が低いため、まずSEOで勝負できます。
検索意図の分類と活用方法については、関連記事「検索意図とは」を参考にしてください。
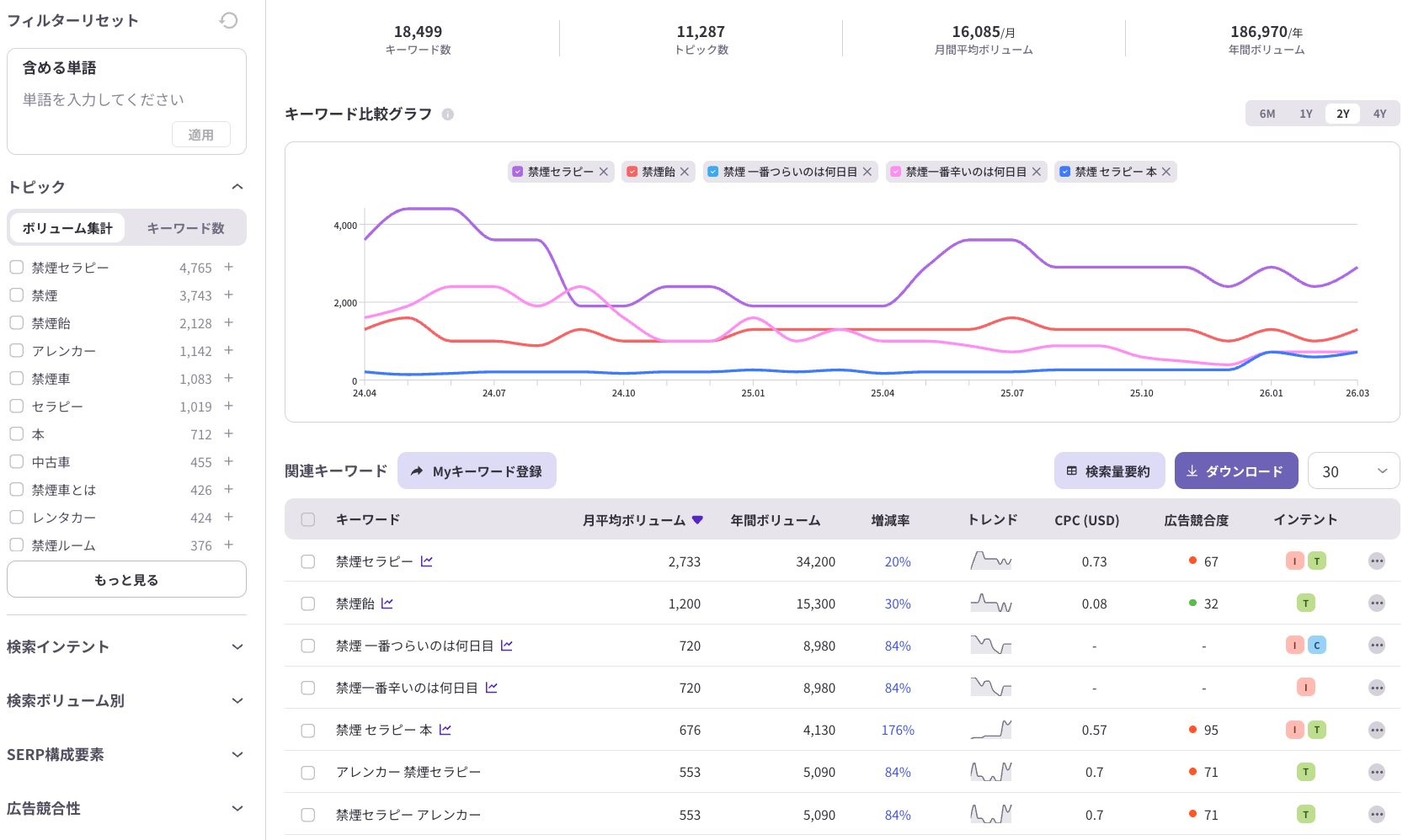
【ヒント】ListeningMindのクエリファインダーでは、特定テーマに関連する検索クエリとその検索意図を一覧で確認できます。情報収集型クエリを洗い出し、AI介在度が高い領域から優先的にLLMOコンテンツを設計するのに活用できます。
ステップ2:AI回答後の検索ジャーニーを把握する
LLMOで「AIに引用された後」を考えている企業はまだ少数です。AIが回答を返したあと、ユーザーは次に何を検索するでしょうか。この「AI回答後の検索行動」を把握することで、AIとの接触後にユーザーを自社サイトへ誘導するコンテンツ設計が可能になります。
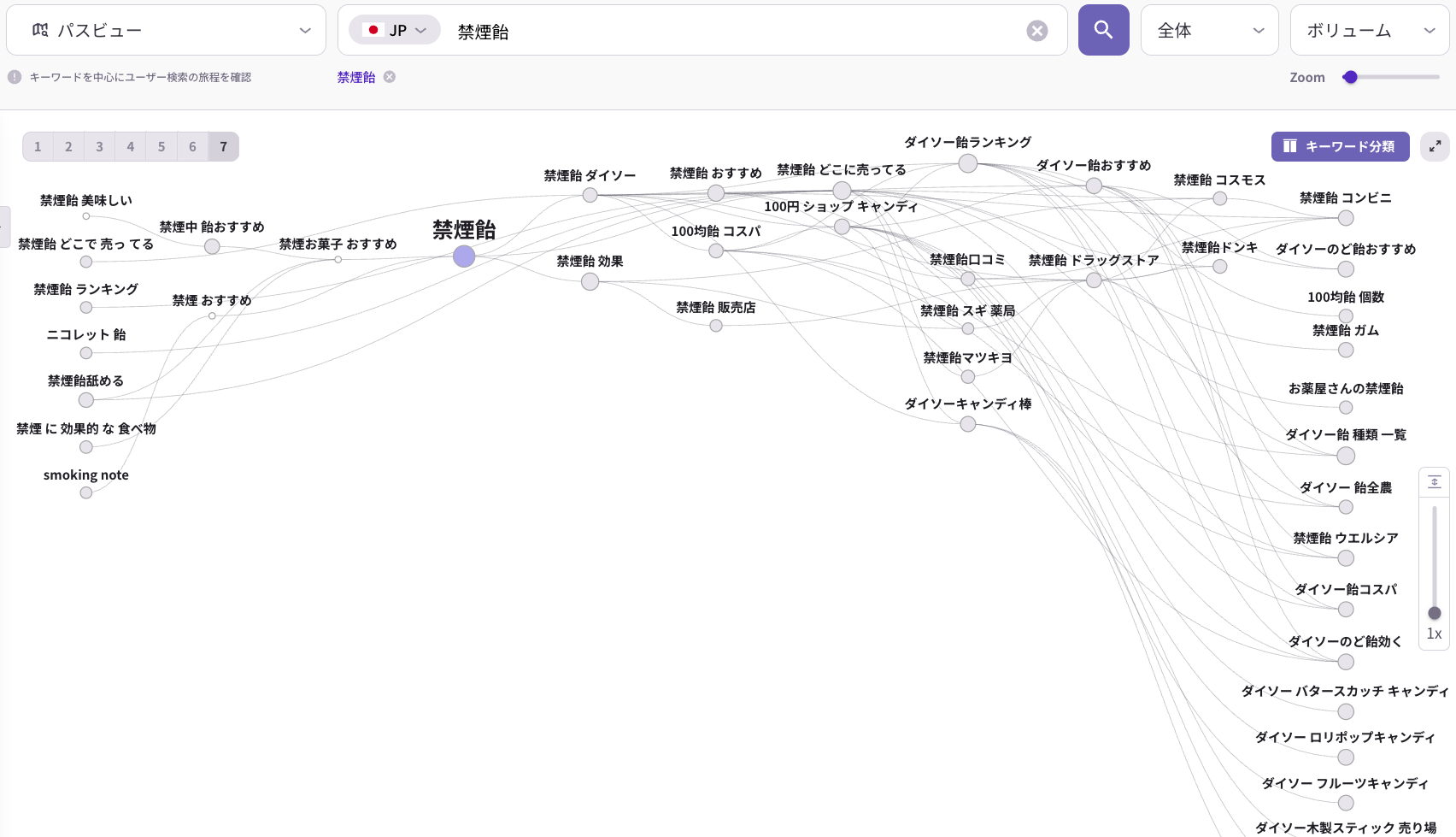
【ヒント】ListeningMindのパスファインダーを使うと、特定キーワードを検索したユーザーが次に何を調べるかという「検索ジャーニー」を可視化できます。AI回答後のユーザー行動を先読みし、そこにコンテンツを置くことで、AI経由の認知をサイト流入・コンバージョンへつなげるための設計ができます。
AI検索がマーケティングに与えている影響の全体像については、関連記事「Google AI検索とマーケティング戦略」を参考にしてください。
LLMO効果測定の3つの指標
LLMOの成果は、従来のSEO指標(検索順位・オーガニック流入数)だけでは測れません。以下の指標を組み合わせて評価します。

① AI言及率(メンション率)
ChatGPT・Gemini・Perplexityなど複数のAIに対して、自社に関連する質問(「〇〇分野のおすすめツールは?」「〇〇に強い会社を教えて」など)を投げかけ、自社名・サービス名が言及されているかを確認します。
評価のポイントは単純な回数ではなく、文脈の質です。「おすすめとして紹介された」「特定のメリットを持つ会社として言及された」といったポジティブな文脈での言及が本質です。月次でモニタリングし、変化を追います。
② サイテーション数の変化
第三者サイトで自社名・ブランド名が言及されているページ数の推移を把握します。被リンクではなく「言及」の量と質を指標として管理します。LLMは信頼性の高い情報源に依存するため、サイテーション数の増減はLLMOへの影響度を間接的に示します。
③ 指名検索数の推移
AI経由でブランドを認知したユーザーが、Googleで直接自社名を検索するケースが増えます。Google Search Consoleで指名キーワードの推移を定期的に確認することで、LLMO施策によるブランド認知効果を間接的に測定できます。
ListeningMindでLLMO戦略を具体化する
LLMOで成果を出すには、単に「AIに引用されやすい記事を作る」だけでは不十分です。重要なのは、どの検索クエリでAIが介在しやすいのか、ユーザーがAI回答を見たあとに何を調べるのか、競合がどのトピックで引用・想起されやすいのかを、データにもとづいて把握することです。
ListeningMindは、日本のユーザーの検索行動データをもとに、LLMO・SEO・コンテンツ戦略を設計できるマーケティングインテリジェンスツールです。
たとえば、ListeningMindを活用すると、以下のような分析が可能になります。
- クエリファインダーで、自社テーマに関連する情報収集型クエリを洗い出し、LLMO対策を優先すべき領域を特定する
- クラスターファインダーで、ユーザーの関心事や関連トピックを可視化し、AIに専門性を認識されやすいトピッククラスターを設計する
- パスファインダーで、特定キーワードを検索したユーザーが次に何を調べるのかを把握し、AI回答後の検索ジャーニーに合わせた導線を作る
- 競合サイトや上位コンテンツを分析し、自社コンテンツに不足しているテーマ・見出し・検索意図を把握する
LLMOは、SEOと同じく「何となく施策を増やす」だけでは成果につながりにくい領域です。自社のターゲットユーザーがどのような疑問を持ち、どの順番で情報を探し、どのタイミングで比較・検討に進むのかを把握したうえで、コンテンツを設計する必要があります。
ListeningMindを使えば、自社に関連する検索クエリ、ユーザーの関心クラスター、検索ジャーニー、競合との差分を一つずつ可視化できます。これにより、AI検索時代においても「ユーザーに見つけられるコンテンツ」「AIに参照されやすい情報源」「最終的に問い合わせにつながる導線」を設計しやすくなります。
自社のクエリや既存コンテンツをもとに、AI検索時代にどこから改善すべきかを実際に確認してみてください。
「自社の場合、どのクエリからLLMO対策を始めるべきか」「既存コンテンツのどこを改善すればAI検索時代に対応できるのか」——こうした疑問をお持ちの方は、お気軽にお問い合わせください。貴社の業界・商材・ターゲットキーワードに合わせて、LLMO戦略の優先順位と具体的なコンテンツ改善ポイントをご提案します。
よくある質問
A. 並行して取り組むことが基本です。LLMはWebページを参照するため、まずSEO基盤(クロールされる構造・高品質なコンテンツ・十分なE-E-A-T)が前提になります。その上でLLMO固有の施策(情報構造化・サイテーション獲得)を積み上げていくアプローチが現実的です。「LLMOに集中するためにSEOを止める」という選択は本末転倒です。AIとSEOの関係については、関連記事「AIとSEO」を参考にしてください。
A. 十分あります。LLMはニッチなテーマや地域特化のコンテンツも評価します。大手サイトが持ちにくい「特定領域の一次情報」や「現場知見」を持つ中小企業は、LLMにとっても価値ある情報源になれます。特定ジャンルに絞った専門コンテンツの積み上げが、LLMOでは有利に働きます。
A. 必須ではありません。GEO/AIOに関するGoogle公式ドキュメントが更新されました。その中では明確にllms.txtなどのファイルは不要を記載されています。
生成AI向けのWebサイト最適化ガイドライン
A. 補助的な効果はあるとされていますが、単体での効果は限定的です。AIが引用するかどうかは、最終的にはコンテンツの質・信頼性・サイテーションの量に依存します。構造化データに過度なリソースをかけるより、コンテンツ品質の向上を優先してください。
A. SEO同様、即効性はありません。コンテンツの構造化やE-E-A-T強化は数ヶ月単位で評価されます。ただし、AIのモデル更新のタイミングで言及状況が変わることがあるため、定期的なモニタリングが重要です。また、サイテーション施策は複数のメディアへの働きかけが必要なため、計画的に進めることが求められます。
A. まず「自社に関連するクエリで、AIがどのような回答を返しているか」を確認することから始めましょう。ChatGPT・Gemini・Perplexityそれぞれで5〜10の質問を投げかけ、自社が言及されているか、競合他社がどう言及されているかを記録します。この現状把握が、施策の優先順位を決める出発点になります。
まとめ
LLMOは「AIの回答に自社を引用させる」最適化手法ですが、特効薬的な「LLMO専用施策」が存在するわけではありません。本質は「AIが信頼できる情報源として繰り返し参照したくなるコンテンツと、それを裏付ける外部評価を積み上げること」です。
本記事で解説した6つの施策を改めて整理します。
- E-E-A-T強化:著者情報の明示、根拠の提示、情報鮮度の管理
- 一次データの公開:自社調査・独自データで引用されやすい情報資産を作る
- コンテンツ構造の最適化:見出し・FAQ・比較表でAIが理解しやすい設計にする
- トピッククラスターの構築:特定テーマへの専門性をLLMに認識させる
- サイテーションの獲得:第三者メディアからの言及を計画的に増やす
- 構造化データの実装:補助として活用。過信せず優先度は低め
また、施策設計の前に「どのクエリでAIが介在しているか」を把握することが戦略の精度を上げます。情報収集型クエリのLLMO対策を先行させ、コマーシャルクエリはSEOで対応する——という優先順位の判断が、限られたリソースを最大化します。
自社のクエリ環境に合わせたLLMO対策の進め方や、既存コンテンツの改善ポイントについて相談したい方は、お気軽にお問い合わせください。
本記事の情報は2026年時点のものです。
執筆者紹介

株式会社 アセントネットワークス ソリューション事業部 シニアアナリスト 吉岡直樹
デジタル系プロダクションの設立の後、NEC(ヒアラブルデバイスUX設計)、JTB(輸出促進支援事業次席顧問)、TBS(Screenless Media Lab. テクニカルフェロー)、NHK(放送100年プロジェクト/データ分析)などへの参加を経て現職。
日本ディープラーニング協会 認定エンジニア (JDLA for ENGINEER 2022#2)、(米)PMI認定 プロジェクトマネジメント・プロフェッショナル (PMP)、経営学MQT 上級 (NOMA)、データサイエンティスト協会 会員 (個人)、日本マネジメント学会 会員 (個人)。
著書:「AIアシスタントのコア・コンセプト/人工知能時代の意思決定プロセスデザイン(BNN:2017)」、「SENSE インターネットの世界は「感覚」に働きかける(日経BP:2022)」
※ NHK 放送100年「メディアが私たちをつくってきた!?」データ分析担当
この記事のタグ
-

マーケティングを極めるためのおすすめの本20選
マーケティング初心者から実務のプロ、経営者まで、幅広い方々に役立つ厳選の20冊をご紹介します。
-

カテゴリーエントリーポイント(CEP)の活用方法と見つけ方
カテゴリーエントリーポイント(CEP)の活用方法と見つけ方についてご紹介します。
-

インテントベースのSEO/動的市場でCEPをつかむ次世代コンテンツ戦略
消費者の意図に焦点を当てた新しいアプローチであり、インテントドリブンなSEOの定義はなぜ重要なのかと活用方法を紹介します。
-

マーケティング担当者必見の11選!ツール導入で迷わない選定ガイド完全版
マーケティング活動の成功には、適切なツールを選ぶことが不可欠。目的別に役立つマーケティングツールを比較し、紹介します。
-

カテゴリーエントリーポイント(CEP)の事例集|ブランド別に見る「想起のきっかけ」
カテゴリーエントリーポイント(CEP)とは何なのか?CEPの事例と見つけ方についてご紹介します。
-
検索意図とは?4タイプの分類・調べ方・SEO記事への活かし方を解説
検索インテントの種類や重要性から活用方法までご紹介しております。
-
ペルソナとは?マーケティングでの意味・作り方・ターゲットとの違いを解説
ペルソナとJobs To Be Doneを組み合わた、ニューペルソナを見つける方法をご紹介します。
-

なぜパスファインダーを使うべきなのか?検索ジャーニーの理解が必要な理由とその方法
パスファインダーで検索経路を可視化し、ユーザーの本当の意図を把握する方法を解説。